We have several very large NetCDF datasets with lots of variables to visualise. I have a gut feeling that file sizes are an issue and there is a bottleneck at the disk to RAM stage, but how do I prove it ? By writing a set of micro-benchmarks to test the various storage and access options. The options are:
1) Storage pattern - NetCDF allows vanilla NetCDF3, Lossy Packing, Lossless Deflation, Chunking and combinations of the aforementioned schemes for storage. If data fidelity is not an issue (as in the case of materialised overviews) , my benchmarks indicate that Lossy Packing is the best way to go.
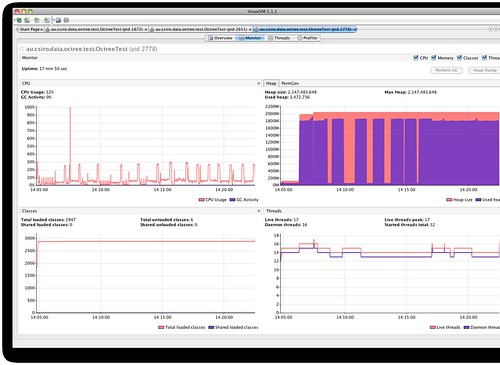
2) Access pattern - The beast under scrutiny was 27GB RAMS Atmospheric model with 50+ variables. The biggest variable chews up 2GB of RAM if you load it all at once. Full data load takes 1000s, while 1/16th load in all dimensions takes 600ms. If just edges are read to perform a bounding box style render that is quicker as well. The exact access pattern used will depend on the volume rendering technique chosen. There are also asymmetries in accessing the beginning and ending of the variables. This indicates linear seeks across files.
3) Access Path - Still need to compare access via the C-library+JNA/JNI rather than pure Java. John Caron seems to have done it a while ago, but I am still agonising over how to activate this experimental code in the current version of the library.
PS: I have got the JNA code working with NetCDF-Java and started a dialog with John.
1) Storage pattern - NetCDF allows vanilla NetCDF3, Lossy Packing, Lossless Deflation, Chunking and combinations of the aforementioned schemes for storage. If data fidelity is not an issue (as in the case of materialised overviews) , my benchmarks indicate that Lossy Packing is the best way to go.
2) Access pattern - The beast under scrutiny was 27GB RAMS Atmospheric model with 50+ variables. The biggest variable chews up 2GB of RAM if you load it all at once. Full data load takes 1000s, while 1/16th load in all dimensions takes 600ms. If just edges are read to perform a bounding box style render that is quicker as well. The exact access pattern used will depend on the volume rendering technique chosen. There are also asymmetries in accessing the beginning and ending of the variables. This indicates linear seeks across files.
3) Access Path - Still need to compare access via the C-library+JNA/JNI rather than pure Java. John Caron seems to have done it a while ago, but I am still agonising over how to activate this experimental code in the current version of the library.
PS: I have got the JNA code working with NetCDF-Java and started a dialog with John.

No comments:
Post a Comment